변수
값이 저장될 Memory 주소의 이름이다. 변수를 호출하면서 변수에 저장된 값을 가져올 수 있다.
C는 & 연산자로 실제 memory의 주소를 가져올 수 있으며, * 연산자로 memory 주소에 저장된 실제값을 가져올 수 있다.
자료구조
array, linked list, stack(LIFO), queue(FIFO), tree 등등이 있다.
binary tree의 순회(traversal): 방향성은 같고 node 방문 순서만 달라진다.
Algorithm
- sort
- O(n^2) -> [selection, insertion, bubble]
- O(nlog(n)) -> [merge, heap, quick, tree]
- search
- O(n) -> linear
- O(log2(n)) -> binary: 정렬이 전제되어야 함
- O(1) -> hash: hash 함수로 값을 저장할 주소를 정함
- recursive
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28
def fibonacci(n): _curr, _next = 0, 1 for _ in range(n): _curr, _next = _next, _curr + _next return _curr def hanoi(n, source, destination, helper): if n==1: print ("Move disk 1 from peg", source, " to peg", destination) return hanoi(n-1, source, helper, destination) print ("Move disk", n, " from peg", source, " to peg", destination) hanoi(n-1, helper, destination, source) def quick_sort(arr): if len(arr) <= 1: return arr pivot = arr[len(arr) // 2] lesser_arr, equal_arr, greater_arr = [], [], [] for num in arr: if num < pivot: lesser_arr.append(num) elif num > pivot: greater_arr.append(num) else: equal_arr.append(num) return quick_sort(lesser_arr) + equal_arr + quick_sort(greater_arr)
Database(DB)
- 구조화되고 체계화된 데이터 모음
- ex) 대학에서 한 학생이 자퇴하는 경우, 학생 관리용 program, 교수 관리용 program, 성적 관리용 program에 들어있는 학생의 정보는 전부 삭제되어야 한다. 이런 중복되는 정보를 통합하여 DB에 공유하고 DBMS는 이 DB 데이터를 입맛대로 조합하여 여러 program이 사용할 수 있도록 한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
SQL
DDL(Data Definition Language): table 생성, 삭제, 변경 (create, alter, drop, rename)
- create table [table name] [column name, type(length)] [column name, type(length)] ...;
- alter table [table name] add [attribute name, type];
- alter table [table name] modify [attribute name, type(length)];
- alter table [table name] drop [attribute name];
- drop table [table name];
DML(Data Manipulation Language): table 내에서의 data 검색, 삽입, 삭제, 갱신 ()
- select
- insert into [table name(column name1, column name2, ...)] values [column value1, column value2, ...]
- update [table name] set [column name1=value1, column name2=value2, ...] where [column name=value];
- delete from [table name] where [column name=value];
DCL(Data Control Language): table의 보안, 무결성 관리
- commit
- rollback
- grant
- revoke
Network
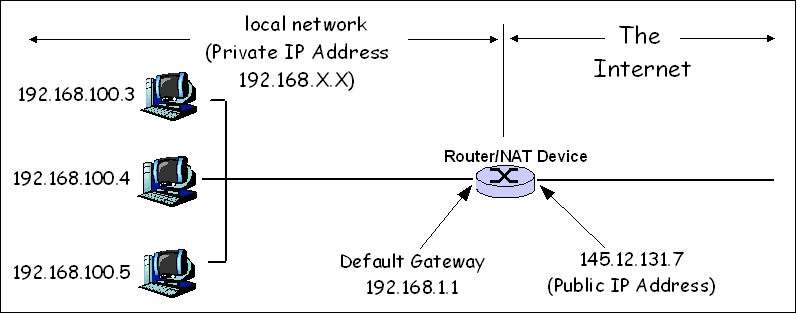
- LAN(Local Area Network): 가까운 거리의 작은 영역의 장치들이 연결됨
WAN(Wide Area Network): 둘 이상의 LAN이 Gateway(router)로 연결됨 -> Gateway가 LAN의 경계
![Desktop View]()
- IP: 인터넷에 연결된 기기를 식별하는 주소
- Port: 연결된 기기(서버)의 program을 식별하는 주소
- CIDR(Classless Inter-Domain Routing)
- 기기가 속해 있는 network, host를 식별하는 데에 사용
- ip 주소를 표현하는 16가지의 bit 중 cidr 수만큼의 bit까지는 network 주소로, 하나의 같은 network로 취급, 즉 gateway 밖으로 나가지 않음
- 2^(32-cidr): 생성 가능한 host의 수
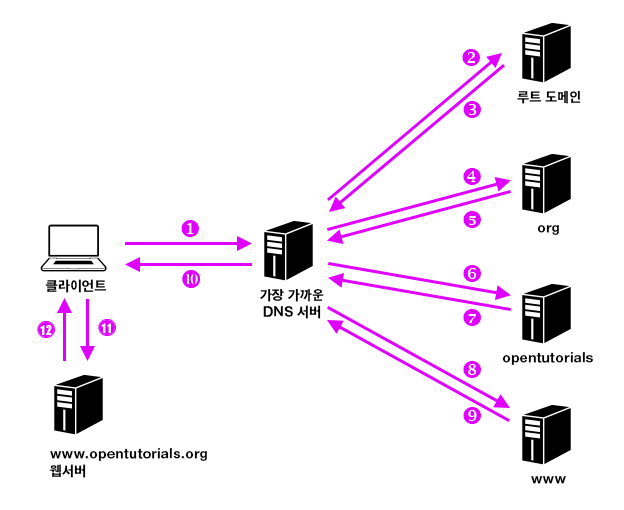
- DNS(Domain Name System)
- DNS 서버가 숫자 형태의 ip 주소를 문자열 형태(domain)로 변환하여 반환한다.
- linux의 경우 /etc/resolv.conf에
nameserver [naveserver의 ip]로 등록한다. - www.example.com의 정보는 example.com의 DNS 서버에 저장되고, example.com의 정보는 com DNS 서버에 저장, com의 정보는 root domain에 저장되는 식으로 계층이 올라간다.
![Desktop View]()
- 인터넷의 동작 과정
- App에서 전송할 데이터와 수신 측의 IP, port를 TCP/IP or UDP SW에 보낸다.
- TCP or UDP SW(4계층)는 데이터 앞에 TCP/UDP header를 추가(encapsulation)하여 IP(3계층)로 보낸다.
- IP SW(3계층)에서 IP header를 추가한 후, Routing Table에서 목적지 주소를 위한 경로를 찾는다.
- 경로를 찾은 후, ARP(Address Resolution Protocol)로 송신 측의 router(gateway) MAC 주소를 알아내어 MAC header(2계층)를 씌운다.
- NIC(Network Interface Controller)에서 데이터를 전기 신호로 변환하여 송신 측의 router로 전송한다.
- 송신 측의 router에서 MAC 주소를 확인하고 MAC header를 제거(decapsulation)한 후 수신 측의 router로 보낸다. (router끼리는 직접 연결되어 있으므로 encapsulation이 필요 없다.)
- router에서 IP header로 수신 측의 MAC 주소를 확인하고 header(2계층)를 추가하여 NIC에서 수신 측의 서버로 보낸다.
- 서버에서 MAC 주소, IP, TCP/UDP header의 정합성을 확인하면서 차례로 제거한다.
- 수신 측 port에 해당하는 App으로 데이터를 보낸다.
- TCP와 UDP는 수신 측에서 응답을 하느냐 하지 않느냐 (TCP는 8번 순서에서 IP header를 제거한 후 ACK를 보낸다.)
- TCP와 UDP는 수신 측에서 응답을 하느냐 하지 않느냐 (TCP는 8번 순서에서 IP header를 제거한 후 ACK를 보낸다.)
- 오류 검출
- VRC(Vertical Redundancy Check): parity bit를 추가하여 오류 검출 (짝수 개의 bit에 오류가 발생할 경우, bit 합의 짝홀이 변경되지 않아 오류 검출 불가능)
- LRC(Longitudinal Redundancy Check): 데이터를 일정하게 쪼개어 각자 parity bit를 추가, 쪼갠 단위만큼의 parity check가 늘어나 VRC보다 더 정확함
- CRC(Cyclic Redundancy Check): 데이터 bit들을 정해진 수로 mod-2 나눗셈을 하고 [나머지]를 중복 정보로 사용 (수신 측에서 데이터 bit들에서 나머지를 추가하여 정해진 수를 mod-2 나누기로 0이 나오는 지로 오류 검사)
- Checksum: 데이터를 n-bit * k개로 나누고 이를 더한 값의 1의 보수를 중복 정보(checksum)로 사용 (수신 측은 동일한 방법으로 데이터를 계산하여 checksum 비교)
보안
- 비밀키 암호화 방식
- 하나의 암호화 키를 사용해서 암호화, 복호화
- 암호화 키를 여러 사람이 공유하므로 유출 가능성이 높음
- 공개키 암호화 방식
- 공개키(public key)로 암호화, 비밀키(private key)로 복호화
- 비밀키만 암호를 풀 수 있으므로 공개키가 공개되어도 보안에 문제 없음
- RSA 암호화 방식
- 적당히 비슷하고 큰 소수 p, q를 곱하여 공개키 n을 생성
(\(p*q = n\)) - (p-1)(q-1) = o일 때, o보다 작고 o과 최대공약수가 1인 서로소 e를 선택
(\(gcd(o, e) = 1 (o < e)\)) - e*d를 o으로 나누었을 때 나머지가 1이 되는 서로소 d를 선택
(\(1 \equiv e*d\mod{o}\)) - 평문 = m, 암호문 = c, 공개키: (n, e), 비밀키: (n, d)
\(c \equiv m^e\mod{n}\)
\(m \equiv c^d\mod{n}\)
- ex) A가 ‘J’를 B에 보내고 받는 과정, p = 11, q = 13, n = 143, o = 120 (‘J’의 ASCII 값은 1001010 = 74)
- $ gcd(o, e) = 1 $ 을 만족하는 e = 23 선택 -> A의 공개키 (n, e) = (143, 23)
- $ e*d \equiv 1\mod{o} $ 을 만족하는 d = 47 선택 -> A의 비밀키 (n, d) = (143, 47)
- $ 74^{23}\mod{143} \equiv 94 $ => A가 B의 공개키 (n, e)로 만든 암호문: 94를 B에게 보낸다.
- $ 94^{47}\mod{143} \equiv 74 $ => B가 자신의 비밀키 (n, d)로 암호문: 94를 해독하여 ‘J’(74)를 얻는다.
- 제 3자가 암호문 94를 가로챈다고 해도, 공개키인 (143, 23)으로는 해독할 수 없다.
- 나머지 연산의 결과가 암호문, 복호문이 되기 때문에 역산이 불가능한 구조라서 대칭키가 될 수 없음
- 적당히 비슷하고 큰 소수 p, q를 곱하여 공개키 n을 생성
참고